This is part 1 of a four-part series that touches on some of the problems associated with selecting the programming features for a “music program”. This part talks about the features of speech and how these may differ from those of music. Parts 2, 3, and 4 will talk about the various characteristics of reeded musical instruments, stringed instruments, and brass instruments respectively.
Modern hearing aids can now offer the capability to be responsive to varying levels of inputs. While most of the work on how it does this is related to speech, perhaps what we have learned from speech can teach us a few things about music. Part 1 of this blog is primarily about speech, and part 2 (next week) is about music.
A hearing aid will generate significant amplification for soft level inputs, less amplification for medium level inputs, and sometimes no amplification for louder level inputs. Many people simply do not need a lot of hearing aid amplification for the louder components of speech (and music).
Many hard of hearing people may say “I can hear fine if people would only speak up a bit” and they are quite correct. So it is understandable why there has been a significant amount of research in this area for speech, but very little for music. Previous blogs have suggested that for some people with quite significant hearing losses, little or no amplification may be required for loud (live) music, and removing the hearing aid may actually be the best strategy.
But what are the “targets” for music when it comes to fitting hearing aids? There are two primary target-based techniques for fitting hearing aids for speech. These are based on the long-term average speech spectrum- the “average” speech if measured over a period of time that serves as a “typical” input to a hearing aid. One of these approaches is based on the work of the National Acoustics Laboratories (NAL) in Australia and the other is based on a Desired Sensation Level (DSL) based on the work of Richard Seewald, Susan Scollie, and their colleagues at Western University in Canada.
Both these approaches use in-depth knowledge of the statistical nature of speech- values of the peaks and the valleys of speech, as well as crest factors (differences between the instantaneous peaks and the long-term, wide-band RMS average of the speech). Interestingly both of these approaches (NAL and DSL) result in similar prescriptive targets, despite having differing approaches and underlying assumptions.
One reason for this is that the long-term average speech spectrum is quite similar from person to person and from language to language. People are, well, people. We all have similar vocal tract lengths and characteristics, so it is understandable that that the long-term average speech spectrum is similar among people and can be used as a generalized input to a hearing aid in order to establish prescriptive outputs for people.
Music is an entirely different type of input to hearing aids. Where speech can be soft (55 dB SPL), medium (65 dB SPL), or loud (80 dB SPL), music can be soft (65 dB SPL), medium (80 dB SPL), or loud (95 dB SPL). Music tends to be shifted up one “loudness” category as compared with speech. There are other statistical differences between speech and music that involve the crest factor and other temporal features; however, a major difference is that music is louder than speech.
So far, this seems rather straightforward. For a music program, adjust “quiet” music to be like medium speech; adjust “medium” music to be like loud speech; and adjust “loud” music to be like very loud speech- perhaps subtract 5-10 dB from the amplification for a music program for loud music compared to what would be programmed for loud speech.
Now it gets a little bit tricky. Can we definitively say that music has well-defined features for soft, medium, and loud levels? Speech is rather straightforward. In speech, the lower-frequency vowels and nasals (called “sonorants”) carry the loudness of speech. There are higher-frequency consonants such as ‘s’ and ‘sh’ but these sounds (called “obstruents”) don’t change much in speaking level. A quiet ‘s’ and a shouted ‘s’ are rather similar in level.
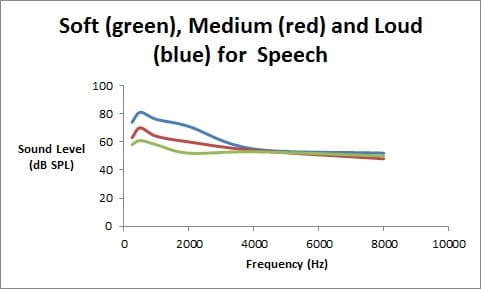
The difference between soft and loud speech is then primarily in the lower-frequency region where the sonorants are. If you compared the shape of the quiet and loud speech spectra, you would see that there is more low-frequency emphasis (where the sonorants are) for loud speech relative to the higher-frequency obstruent consonants, than for quiet speech. For loud speech, the spectrum may fall off at about 8 dB/octave whereas for quiet speech it may fall off at only 5-6 dB/octave. You simply cannot utter a loud ‘s’ in the same way that you can utter a loud ‘a’. As the speech gets louder, the lower-frequency vowel sound energy grows faster than the higher-frequency consonant energy.
This is complex, but it is straightforward and has been implemented in modern hearing aid technology. The figure shows the relative shapes of the various speech spectra for quiet, medium and loud speech. Next week’s blog will delve into how this differs with music instead of speech.