
Welcome back from the Christmas break. I hope it was peaceful and relaxing.
This is Part 3 in a four-part series that touches on some of the problems associated with selecting the programming features for a “music program”. Two weeks ago, I talked about the features of speech and how they may differ from those of music, as well as the various characteristics of reeded musical instruments.
Examining the differences between soft, medium, and loud playing levels for string musical instruments, a different scenario rears its head. As can be seen in the figure below, stringed instruments have a different pattern for soft, medium, and loud speech and also for soft, medium, and loud reeded woodwinds.
In short, as the speaking level increases, there is a relative increase in the lower-frequency region (the vowels and nasals) compared to that for the higher frequency consonants (the siblants, fricatives, and affricates). One simply cannot shout an ‘s’ as loudly as one can shout the vowel ‘a’. Speech therefore has a “low-frequency ballooning” effect as the speaking level increases.
And, in short (or is it too late?) for reeded woodwinds, the only change as a clarinet or sax is played at a louder level is in the higher frequency regions. The lower frequency fundamental energy doesn’t change at all when playing a soft note or a loud note. Reeded instruments therefore have a “high-frequency ballooning” effect as the playing level increases.
Stringed instruments are, again, an entirely different animal. They are acoustically grouped together and called “half wave length resonators,” meaning that they have evenly spaced integer multiples of the fundamental (note name) frequency. Our vocal chords also function as half wave length resonators and therefore speech has evenly spaced integer multiples of the fundamental. However, this is where the similarity ends.
When you play a violin (guitar, viola, cello, bass, or even piano) at a soft level, there is a well-defined spectrum. And when you play these instruments at a very loud level, this spectral shape is maintained. If the low-frequency fundamental energy increases by 10 dB, the high-frequency harmonic energy also increases by exactly 10 dB. In stringed instruments, the level of the spectrum defines the playing level and this can be seen by changes at 250 Hz as easily as at 4000 Hz. The figure below shows this spectral similarity for all playing levels. There is no “low-frequency ballooning” as seen in speech (part 1 of this blog) or “high-frequency ballooning” as seen with reeded instruments (part 2 of this blog).
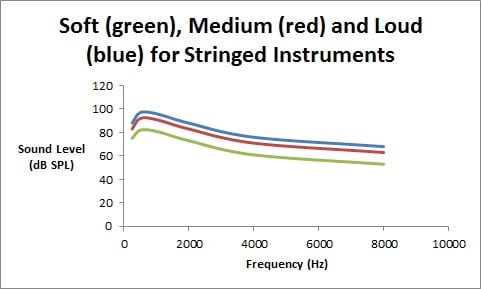
In this sense, when a stringed musical instrument is played louder, it is identical to listening on a radio, or MP3 player, but with the volume turned up. This does not alter the spectral content. Turning up the volume will be similar to listening to a violin played at a louder level, and turning down the volume will be similar to listening to a violin played at a softer level.
For people with a high-frequency hearing loss such as from presbycusis or noise exposure – the two most common types of hearing loss – if they are not wearing hearing aids, the following observations may be made:
1. If speech is sufficiently loud, they may have little or no difficulty.
2. If reeded instruments are sufficiently loud, they may have difficulty appreciating the “balance” of the music.
If stringed instruments are sufficiently loud, they may present no difficulty for a mild hearing loss, but with a more significant hearing loss, they would lose the “high-frequency harmonic structure and loudness balance” for the music.
If a hard-of-hearing person attends a classical or pop concert where there may be a “string-heavy” environment, they should sit as close to the front as possible. I am not convinced that hearing aids with a single level-dependent program will be sufficient to allow the wearer to appreciate the subtlety of all musical instruments. The same goes for an assistive listening device- again, any amplification that is designed for simple amplification (e.g., an FM or infra-red theater listening system) would not be sufficient… I think…
I, and other smarter people than me, have written in the past that the compression characteristics of the hearing aid are related to the sensorineural damage in the cochlea, and given primarily outer hair cell damage (damage less than about 60 dB HL), compression should be set according to the pathological loudness growth curves and NOT the nature of the input spectrum. That is, the compression features of a “music program” should be identical to that of a “speech in quiet” program.
So…. I could see an experiment where listeners can use a “music program” that is not level dependent- gives the same amplification regardless of input (i.e., linear), and one that has the same level-dependent compression characteristics of speech (i.e., more gain for soft level inputs and gradually less for louder inputs). This would be testable and would make for an excellent Capstone study for any interested AuD student.
If in a string-heavy (e.g., classical) music environment, I would recommend simply spending the extra money for a close seat, and removing the hearing aids, or if hearing aids are used, a “low tech” linear program may be optimal. I would not suggest this in other “non-heavy stringed” environments such as jazz or blues. But until the experiment is performed to test this (linear vs. same compression characteristics in a speech in quiet program), I am not sure…. How’s that for sitting on the fence!



