
This week, host Amyn Amlani introduces us to Earzz, an innovative sound recognition device and monitoring system. He is joined by the founder of Earzz, Prad Thiruvenkatanathan, who sheds light on the technology’s unique capabilities and its potential impact for those with hearing loss.
Unlike most other hearing-related technologies that focus on speech or speech in noise, Earzz specializes in recognizing non-speech stimuli. It offers a fresh perspective on sound monitoring, enabling users to customize their alerts for various sounds, from doorbells to water leaks, making it a useful tool for both individuals with hearing loss and those with normal hearing.
Full Episode Transcript
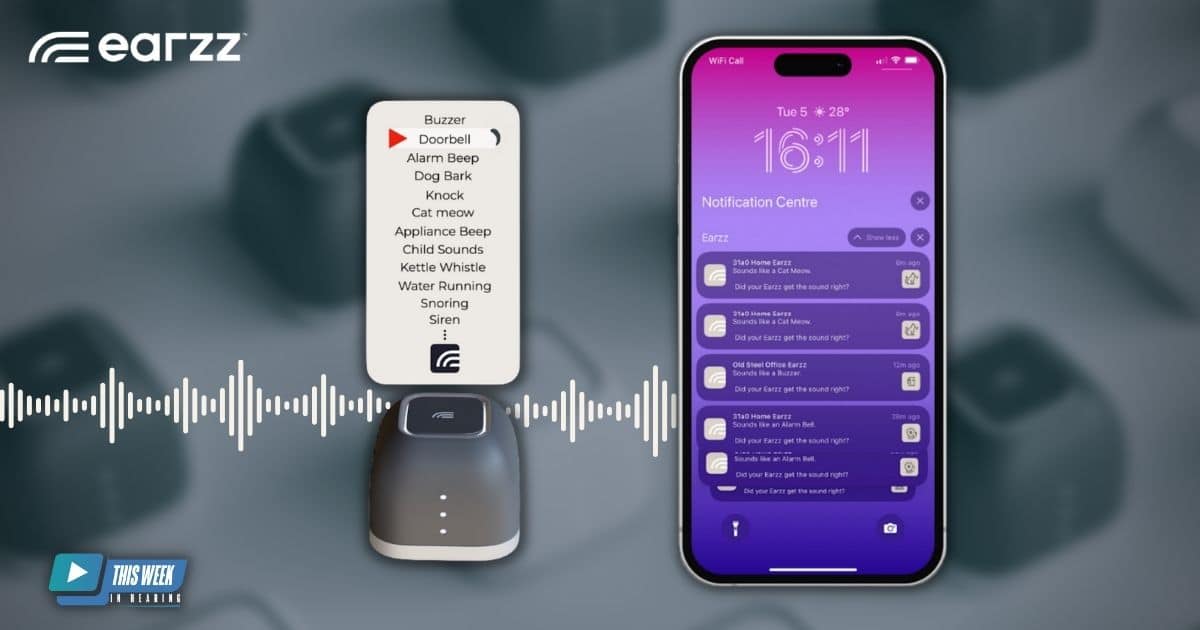
Welcome to another episode of this Week in Hearing. I’m your moderator, Amyn Amlani, and I’m here today with what is a really fascinating story that we’re going to share today. As most of you are aware, much of the technology in the hearing care space has to do with technology that deals with speech or speech in noise. And today we’re actually going to be talking with a company that is out of the UK that specializes in non speech stimuli. And so with me today is the founder, Prad. And I appreciate you taking the time to talk to us about you, your product, and the services that you offer. Thank you so much. So please, if you want, go ahead and share a little bit about you and the company before we get started into the product. All right, well, thank you so much, Amyn, for having me, and thanks so much to all your listeners for spending the time. I’m Prad Thiruvenkatanathan, and I’m the founder of Earzz. So, in essence, Earzz makes these little things that you see over here. These are smart listening devices that listen for any sounds that you choose, for it to listen for. So, in essence, you could leave this device behind anywhere in your home, choose the sound that you want it to recognize, and then it sends you an alert on your smartphone, watches, and tablets when those specific sounds are heard. So the idea for Earzz is something that was born out of a genuine need I faced as a busy parent. I’ve got two children myself, two sons. Love them to death, but they do bring the home down. And when my first son was born, my wife and I would often go downstairs, we would rock him to sleep, leave him in his bed, and go downstairs. And it became very hard for us to hear him when he was uneasy, right? So if he started crying, it’s something that we just wouldn’t hear. And that’s when the first need came in. And so we went and bought a baby monitor, which would flash a light every time there is a sound. And that was useful in the sense that we would see the sound, I mean, the light flashing. And then I would run upstairs just to check that everything was okay. And I would realize that my son was fine was a false positive. It was just some noise that often moving around him as an example. And that’s when the first need for specificity came in. So I wanted something that was a bit more specific that could actually stand the sound of a baby crying or baby whining instead of just setting the alerts for any sound that it was capturing. There were also times when I would often take my family out to the garden and we’d be playing in the garden. And when that happened, if somebody knocked on the door, we just wouldn’t hear it. And I’ve got a PhD in engineering from Cambridge and have done some work in acoustics and AI myself. So I knew we could build something that could actually listen for these sounds. So I was then thinking, in that incident, in that specific incident with the knock was missed. I was thinking I needed to go buy a portable doorbell. And I again spent some money both on the baby monitor and the portable doorbell. And that’s sort of when the idea struck me. Why can’t we have one device that could listen for all these different sounds and alert me when the sounds that I want are being listened to by the device? I began searching the market to find a device that would help me do this, but just couldn’t find any that had the sounds I wanted and also could alert me in the way I wanted. So before I began working on the project myself, I started asking others. So I went to other people like me, and by that I mean busy parents. And they all came, turned around and said, yeah, this is something that we would use. I used a baby monitor. I spent £300 pounds on something like that, but I don’t even know where it is today because I have no use for it. It lasted eight months and then I don’t know where it is. So having something that could be interchangeably used for a whole bunch of different purposes would be super useful. And we ended up getting very positive feedback and we started gathering what sounds would be interesting for them, right? And that was just in the busy parents demographic, if you can put it that way. I then started expanding my horizons. I started speaking with others who didn’t have pets or children and I was asking them if they would find something like this useful. And I was speaking with my wife’s colleague at the time and he said, it was COVID time as well, So people were often working from home. And he was saying, well, I use my headphone a lot, and when I grab my headphones on, I just don’t know when the doorbell is ringing or when someone opens the door or even if the appliance goes off. So something like this that could actually give me alerts for those specific sounds that I’m interested in would be extremely valuable. And I was ardently writing everything that he was saying down just to understand his specific pain point. And that’s when he mentioned something that changed the way we looked at the problem, right? So he said, I’ll tell you who this is going to be extremely useful for, and it’s those with hearing loss. And I was then asking, I was intrigued, I was, okay, I can understand why this would definitely be valuable, but can you tell me a bit more? And he said his mother was deaf from birth and she’s been using alerting devices in her home for a long time. So I asked him to expand. What do you mean by alerting devices? And he said, these are two devices that she uses, one for the doorbell. So if somebody rings the doorbell, flashes a light, so she knows someone’s at the door and even if fire alarm goes off, there’s another light that flashes. And he said the biggest pain point for her was she kept missing these often because you need to be in the room where the light is flashing if someone was at the door. And he said these are also single purpose, so you would have one light for specific applications and so these could end up being quite expensive if you really want to understand the range of sounds and access the range of sounds better at home him and so he said something that could vibrate, something that could give a visual alert that could also have some haptic feedback, maybe on the wrist, on the hand, in a smartwatch would definitely be valuable. And having one device that could actually recognize a whole bunch of sounds would really change, would be quite game changing. So that’s sort of when the idea came in and we started exploring that a lot more and we started engaging a lot more and we realized how many sounds were actually missed. Right, so me having hearing, good hearing, I can tell you that these are things that I take for granted and it’s very important that we don’t take. I mean, having a device that could actually let you access things and connect with those sounds is extremely valuable even for people with good hearing. So I can only imagine how it would be for people who don’t have that, who have some sort of hearing loss. Right. So we could recognize that as a big pain point and then we started really going after understanding what that pain point was and we began building all that into a product, which is what this is. So this is something we’ve just launched in the market as of a week ago. So this is launched in the UK market. We did run a Kickstarter campaign for this to check if there was enough traction, which had very good reception. And we ended up getting fully funded in a matter of four days since we launched. So we knew there was a market here and we then took that concept, built that into a full product, which we’ve just launched and we’ve been getting some good feedback as well on it. Well, first of all, congratulations. I know that’s always a huge step in the right direction. Number two, as an audiologist and as someone who’s taught in academia for decades, the alerting system technology really hasn’t kept up the same as hearing aid technology has. So it’s nice that the evolution is starting to take place in this other segment, which is important, as you pointed out, for individuals who have to be in the same room with the technology that’s available today. And just so for clarification purposes. Right. The device that you have, at least what I was able to gather from some of my research before we got on here was there’s a library of non speech stimuli sounds. These sounds are captured by this, I’m going to call it a pod because I’m not sure exactly what it is that you place in a room. And my understanding is you’ll need to place multiple ones in different rooms depending on how you want those sounds to be captured on your cell phone. And then it alerts your phone in some way, as you pointed out. Whether it’s Haptic, whether it’s a message or what have you, maybe an email, I’m not sure that then allows the individual to notice that something is happening. And then I’m assuming that some sort of a registry that’s kept that says this happened. So if you look back. In a month’s time and say, hey, my doorbell rang 20 times and this is the typical time that my Amazon guy is going to deliver. Yeah. So just to explain what the product does, this the pod as you called it, the sensor or the monitor, there’s something that you leave in the room that you want the sound to be captured and then you choose the sounds that you want this device to listen for. So it could be as an example, you may leave this in your hallway and you may choose doorknock doorbell as the two sounds that you’re interested in. And the moment there is a doorbell, the device listens to that audio file. It then sends a two second packet of that audio file to our cloud endpoint, where we process the data using our AI models, which then tells that, well, I’m seeing a sound that matches that of a doorbell as an example. And then it sends an alert to the user’s mobile device. So which is the app through which you select the sounds that you want the device to capture or listen for. And you would have a push notification. So it sends a notification saying, hey, there’s a doorbell with an icon, with an image, which also is connected, may be connected to your smartwatch. And you would see the same feedback coming in your smartwatch as a vibration and as a visual alert. And what’s quite interesting about what we are doing, which is quite markedly different to what you may have outside, is the ability to feedback. So as an example, if you are hearing something and the device is recognizing something very similar to a knock, a thump as an example, may sound like a knock at some time. So if you do get a knock being recognized by the device, each and every notification is pushed with a question that goes with it. This sounds like a knock. Did your ears get the sound right? Yes or no? And the moment you say yes or no, it reinforces the model. The AI model then starts learning as you start pushing more and more data. So the more accurate information you provide, the more accurate the model gets and you end up having better and more improved sensitivity and accuracy in your device itself. Really interesting. So those pods, just me go back to that for just 1 second. What is the range for those pods? Is it 30 meters or sorry, 10 meters? 30ft? What are we looking at here? So it depends, it’s hard to quantify that number purely because it depends on number of factors. It depends on how loud the sound is. So if the sound is very feeble and if I say something like two or 3 meters, then if the sound is very feeble, it’s hard for it to become. But if the sound is loud, again, you could go much further. An example, I’ve picked up water running sound from 10 meters away because the shower makes a lot of noise sometimes, so that’s something that you could pick up. But again, feeble sounds may not be picked up that easily. So just on this, we’ve had some feedback saying it’ll be useful for the user to control the sensitivity in the mic as well. So that’s a new feature that adopting. Again, just to expand the range, if you so choose. But. Some repercussions in terms of the AI model trying to understand even the minute-est of sounds that you’re trying to capture. So that’s something we’re working with. But having said that, it depends. It’s hard to quantify the number is the answer. And then from the spectral characteristics standpoint, a little bit about what are the implications if you are in a reverberant environment or if you have a lot of background noise, how sensitive is your system to picking up what is the target versus what is the noise, so to speak? Excellent question. So in terms of our training cycles, so let me run you through how the AI models are trained. Right? So when we start teaching the models a specific sound, we don’t just train it with that one sound type and that’s it. So we take the sound itself, we extract what we call audio feature images. So we don’t actually process sounds, so we convert sounds into images and those images are the ones we process. And we then start laying different things onto the image, which has a reverberation effect. You could have noise, background noise, a vacuum cleaner noise, you’re surrounded at home by world filled sounds, right? So we then start laying all these different sounds on top. So the AI model understands that. Look, while we’re trying to go after this one specific sound, it could be a knock, it could be any of the sounds that you’re training it for. It could be in the presence of a whole bunch of other things. You’re never going to have knock in pristine form anywhere. So you’re always going to have some element of noise at. And so the AI model tries to learn these scenarios and all of them are trained with those scenarios in mind. So when you put it in the real world setting, it expects that you’re not going to have pristine knock coming at you. You’re going to have some level of operation, some level of background noise. It could be TV playing, music playing, it could be a whole bunch of things in the background, but it still picks up the knock, which is pretty interesting. I’d love to give you one so you can try it too. I would love that. Thank you. No, this is a great concept, so that’s really helpful. And then my next question related to that is you have this library, and I’m assuming just started the library is it’s got some features in there, but it’s not comprehensive at this point. No, develop that. Can you think a little bit about what you have and where you plan to go with your yeah, okay. So in terms of the sound library itself, we’ve got about 15 sounds already in the library. So these are pretrained and we have the intent of constantly growing it. So it’s going to be ever growing. So we’re going to keep adding new sounds to it. As an example since launch, so we launched last week, as I said, and it’s been a weekend. We’ve had some users come back now and say they want a telephone. So they said, sound of a buzzer. Sound a bit like a telephone. They also want telephone to be picked up as a sound. That they want that to be recognized and we got that feedback, I think three days ago and we’ve started work on it. We are already close to finishing the full test and we’ll be launching that this week. So that’s the speed with which we’re going to go. Right, so we’re going to finish that. We’ve also got a couple of Kickstarter backers who come back saying, I love the variety of use cases here, but I also want glass smash, so I want the sound of a glass smash being heard by the Earzz and recognized. So that’s something we’ve also now begun working on. So we’ll finish off with telephone release and then our intent is to within the next week or two, we want to release glass smash as well. So you’re going to have two additional labels being incorporated and we want to keep growing this. So we always go back to users and ask for new sounds and we’ve already got a few. We’ve got dog wimper as a new sound that people want to input into the box, but they also want whimpers. Some pet owners have asked for that. We’ve got screams, so child screaming, so we’ve already got child sounds at home, so they want screams as well as there’s another label, so all of these are now being documented, but we are beginning to roll them out one after the other. And our intent is to constantly keep growing the number of sounds that we have available. So just because we have 15 today, it’s not going to be 15 tomorrow, it’s going to keep growing and it’s going to constantly evolve and that’s the intent behind this. And with your feedback, you being a user, as you start using these, you may start seeing results and as you start feeding them back, all of your feedback is going to get incorporated into the AI model to get better and better and better as well. That’s interesting and you brought up an interesting point and that is that you’re engaging with your consumers who are actually using this product. Yes. Do you have any information that you can share in terms of their thoughts, their perceptions, their satisfaction, their benefits, those kinds of things, as they’re starting to incorporate these into their daily lives? Absolutely. So in terms of where we’ve got to, we have begun shipping our first products out and we are now seeing people actually using it in real life. As I said, we were also starting to get quite a lot of feedback from them. One of them, in fact, this was about a month back when we shipped out our first products to our Kickstarter backers. One of them came to our Facebook page and without telling any of us, he just written, ‘I loved mine’ and you wouldn’t believe the satisfaction we got. See, that is the first comment. So as a startup, you can imagine how nervous we would be to release any new product out to the market. But when we first saw that, we were just ecstatic. Everybody walked in the next day with a smile in our faces, right? It was an amazing moment. And we are a small company, so everybody really cares about what we’re doing. And it was a beautiful moment there. And since then, we’ve also got one person who’s now purchased it, and many of them are very appreciative of what we’re doing. So one of them came back and said, thank you of building this and all of these, I mean, by email. So we’ve got those in writing as well. Thank you for building such a useful product, he said. And again, these are things that we really love to see and we are seeing some good feedback. There are some constructive feedback as well, like the lack of glass smash, the lack of these other sounds which we’ve heard from Kickstarter backers as well. And we are looking at adding all of those, which is when we realize, look, I think one size doesn’t fit all and it comes to sound, your requirements may be different to mine. So we just need to keep adding and building on the number of sounds as well. One of the key feedback in terms of features that we’ve got is also integration with today’s smart home devices. So many of them have come back saying, I love the fact that yours is picking up all of these sounds and sending me notifications, but can you help me automate things in my house based on the sounds? Use Earzz notification of the trigger to do something else. As an example, if I hear a knock, can you get Earzz to connect to a smart light which switches on the light web watch? So can you do that? Was one of the questions. And immediately we had a flurry of other comments come in from our user saying, hey, I love that. Once the washing is done, can you make an announcement to my smart speaker that my load is complete? And then I have a cat once cat meows, can I open up the cat feed automatically? All of a sudden, everybody wants to use sounds as triggers in their homes, which is fantastic, right? So we then started thinking of how to incorporate that. So that’s a new feature that we are now planning on launching and we are now looking at actively integrating us with IFTTT, which is a smart home assistant connectivity tool, which we are now looking at. So once that is done, you can actually do all this and you can keep adding more sounds as well. And what’s interesting about the IFTTT is the hearing aids also utilize this without putting the cart before the horse because they don’t know this conversation and they don’t say anything that might get you in trouble with proprietary information. Is there an opportunity for you to potentially partner with hearing aid manufacturers to use your device in a way that’s meaningful for them? Absolutely. I think in terms of announcements, if you are wearing a hearing aid, that’s something you can do. So as an announcement, it would connect to Alexa, connect to Google Home Assistant, it can connect to a whole bunch of different things that could facilitate all of these interactions as well. It could make announcements through your hearing aid. I know there are some hearing aids that already connect to smart home assistants today, so again, it’s all cloud based. So integrating becomes very easy for us, but what we want is for us to get a very robust AI model and through user feedback, it’s improving constantly. So as it evolves as an AI model and starts understanding the sounds of the world, the applications are really endless. So you could start using it for a whole bunch of things, not just for smart home automations, for other use cases as well. Interesting, this just popped into my head. So we’re going to go back to a technical question. What’s the delay time, if you will, between the actual analog knock or the glass breaking and the time that the individual gets that message? Cool. In terms of what we are seeing. So if you are on a good WiFi so it’s all based on WiFi. So the way it works is the moment there is a knock, the sound packet of 2 seconds goes to the cloud and the processing happens on the cloud. So the end to end delay that we’re seeing from the time you finish knocking to when you get the notification is between three and 5 seconds. That’s what we are consistently seeing. But having said that, it depends on your network. So if you are in a part of the home where the WiFi is not very good, or if you are, it’s network dependent is the honest answer. But the three to 5 seconds we’ve now sent our users are now all over Europe and in the US as well. And interestingly, we’ve had one person use it in his home in Florida, but he’s UK based, so he gets his notifications within four to 5 seconds. So the moment there is a water leak in his home in Florida, he’s sitting here in London and he gets a notification 5 seconds. So it’s pretty cool when you think about it. So you could be anywhere in the world and as long as you have a good connection, you get the that’s really cool. This is a little bit different, but we use it too and we travel our doors to have an app and when it opens we get a notification that the door. There you go. For example, if one of the kids who doesn’t live at home is now home, we know that they’ve arrived safely because imagine the same use case now. So if you had the Earzz device, you could select child sound. So you know exactly when your children are back. It’ll listen and try to understand the pattern of children. It would know when the door bell has rung. It’ll know a whole bunch of different sounds and all without pointing a single camera at anybody. That’s really cool. And then what about privacy? How does the privacy work here? Are there any issues with privacy? Excellent question. So this is something that has come up several times during my conversations with people. So they talk about smart home assistants and how it recognizes voices, but what they’ve done is try to move away from that. And we build the AI entirely to recognize sounds and not speech. We purposefully treat speech as noise. So anytime there is speech, when I talk about noise and the plethora of other sounds that may surround you in your home speech is definitely one of them. So let me explain the end to end here so it becomes very clear as to what we’re doing. So the moment the sounds an audible sound, is captured the Earzz device, packets it into a two second file audio file, which is then encrypted. and sent to our cloud endpoint. And as soon as it hits the cloud endpoint, we extract what we call the featured images, which I talked about. It’s based on image data, and that image is what is then used by the AI model to infer if the sound that you’ve chosen is present or not. And just to be very clear, as soon as that happens, the audio file is gone, it’s deleted. So we don’t have any old linked your recordings, audio recordings, we don’t keep any of that and we don’t use any of that for our training. So as soon as the two second packet is landed, it’s gone. And you can’t work backwards from the image to the sound either, the actual audio file either. So that way what we keep is just the feature image and even that feature image is only kept if you give us feedback saying, hey, this is correct or this is wrong. So the AI can learn from it and that’s about it. So in terms of privacy, you don’t even keep continuous recordings either. So we can’t stitch a sentence together, we can’t do any of it. The two second file comes in, it looks for sounds within the two second file. If it’s not there, it’s deleted. And even if it is there, sound is deleted. And unless you give feedback, the image itself is deleted. So there is nothing that’s actually kept. So your privacy remains protected and your speech remains yours. None of that is actually being kept by us. That’s really cool. So let’s now take this to the clinic. So, as a provider, if I’m interested in your product, number one, can I get it in the US? Because it’s available in Europe, as you said, can I get it in the US? And then, number two, where would people go? To get more information about your product, you can visit earzz.com. That’s our website. You would have a lot of information about the product itself. Do you have any further questions, please do reach out to us at [email protected] So that’s our email, so please do feel free to write to us in terms of availability in the US, our Kickstarter campaign was live in Europe, USA and the UK as well, EU, UK and USA. And this is because we’ve got compliance for the product in all of these geographies. In terms of the product launch itself, we’ve started our journey in the UK. Being a British company, it makes sense for us to start in our hometown and expand from there. So we’ve started in the UK, but if everything goes to plan, we do wish to expand it to the US. In terms of the Kickstarter backing, nearly half of our backers were US based, so we know there is a big market, people like it there, and this is something that has proven to show some traction in the US as well. So we definitely wish to expand there, but just not yet. Until we as a company, we are a very small business. We’ve just started, so our journey has just begun, so we want to learn to walk before we run, so expanding ourselves and spreading ourselves too thin may be detrimental at this point, which is why we just started in the UK. If everything goes to plan, then we will definitely. To expand. Wow. It sounds like you’ve got something that’s very unique, something that’s well needed, something that you’re trying to expand, an area that hasn’t had much expansion. And of course, there’s a critical need as there’s more and more people with hearing loss and as the world becomes noisier and noisier with all the things that are going on. So I have being environmentally aware is really critical, and it sounds like you’re doing all the right things. So I see a lot of success in your future. Thank you so much. Any last words to our audience before we conclude here? Well, I think making sounds more accessible is something that we genuinely care about. It here, and we know there is a huge potential here to unlock, but we can only go on the journey with people, so we can’t go alone. So if you are interested and if you wish to speak with us, know more about the product, please do reach out, and we’d be happy to help anytime. And if you just want to know more about any specific feature, even if you have a new idea on what we need to be doing, then please do reach out to us, and we’ll try to incorporate as much as we can into a robot. Wow. Thank you. And again, best of luck as you guys move forward, and we look forward to hearing more success stories and then eventually having this product jump across the pond so that we can, of course, dispense it here. And I’d be really curious to catch up with you guys down the road and see how much you’ve grown and what that consumer base is now doing and then the growth of that library as well. Yeah, absolutely. Be happy to come back. Well, we appreciate your time and we’ll be in touch soon. Thank you. Thanks a lot.
**Earzz is offering a special discount code to interested readers in the UK with the code “HHTM435N,” providing an extra £5 off any ongoing website promotions
Be sure to subscribe to the TWIH YouTube channel for the latest episodes each week and follow This Week in Hearing on LinkedIn and Twitter.
Prefer to listen on the go? Tune into the TWIH Podcast on your favorite podcast streaming service, including Apple, Spotify, Google and more.
About the Panel
 Prad Thiruvenkatanathan is the Founder and Chief Executive Officer at Earzz. Earzz, a unique sound monitoring system, distinguishes itself by recognizing non-speech sounds, providing a customizable alert system that benefits individuals with hearing loss and those with normal hearing, offering a new dimension in sound monitoring solutions.
Prad Thiruvenkatanathan is the Founder and Chief Executive Officer at Earzz. Earzz, a unique sound monitoring system, distinguishes itself by recognizing non-speech sounds, providing a customizable alert system that benefits individuals with hearing loss and those with normal hearing, offering a new dimension in sound monitoring solutions.
 Amyn M. Amlani, PhD, is President of Otolithic, LLC, a consulting firm that provides competitive market analysis and support strategy, economic and financial assessments, segment targeting strategies and tactics, professional development, and consumer insights. Dr. Amlani has been in hearing care for 25+ years, with extensive professional experience in the independent and medical audiology practice channels, as an academic and scholar, and in industry. Dr. Amlani also serves as section editor of Hearing Economics for Hearing Health & Technology Matters (HHTM).
Amyn M. Amlani, PhD, is President of Otolithic, LLC, a consulting firm that provides competitive market analysis and support strategy, economic and financial assessments, segment targeting strategies and tactics, professional development, and consumer insights. Dr. Amlani has been in hearing care for 25+ years, with extensive professional experience in the independent and medical audiology practice channels, as an academic and scholar, and in industry. Dr. Amlani also serves as section editor of Hearing Economics for Hearing Health & Technology Matters (HHTM).


