
By H. Christopher Schweitzer and Robin C. Donnelly
Considerable work has been devoted over the years to constructing a golden prescription by which to set the gain/frequency properties of hearing aids on the basis of the audiogram. But for every icon, the time comes for re-examination.
At the risk of condemnation by orthodox professionals, we suggest that the pure-tone audiogram, while unquestionably valuable for the otologic diagnostic purpose for which it was intended, is a candidate for iconoclastic consideration. Volumes could be written about the limitations of the classic audiometric method (CAM) for hearing aid purpose, but for this space-limited blog, we will focus briefly on four points of argument.
FAILINGS OF CLASSIC AUDIOMETRY FOR FITTING HEARING AIDS
We will not address here the numerous attempts that have been made to generate “prescriptions” of electroacoustic properties in sensorily damaged ears. Instead, we’ll start with the “splitting head” problem as a first-level CAM issue.
Every hearing care professional is undoubtedly aware that the auditory system is an incredibly robust masterpiece of binaural input analysis, capable of detecting time-of-arrival differences at the two inputs (ears) of as little as 7 millionths of a second. Yet, the first step of every “hearing test” is to separate the ears into the unnatural state of monaural isolation. That is done despite the fact that inter-ear communication in neural wiring commences even at threshold levels.
The real-world hearing system is a phased array for hearing in open space. So, at the very start of data collection, the examining microscope is adjusted past the whole system in a classic reductionist procedure. Separate postings in O’s and X’s of detection levels for each ear give little hint of the synergy of the two ears working in their natural state that enables not only precise azimuthal localization, but also crucial auditory object formation for following a desired target voice in a flutter of competing sounds.
Next, there is a problem of “time-less-ness.” The presentation of sinusoids plotted in the two dimensions of Level versus Frequency completely removes the dimension of Time. The pure tones are all deliberately constructed to be half a second long in audiometric “pulsed” mode, but are often much longer when presented manually. However, as Delattre et al. point out, speech is clearly a patterned sequence of change over time and contains perceptual cues as brief as 20 milliseconds or even less in fast-running speech.
Prosody, melody, intonation, and articulatory differential cues get no proper mapping on an audiogram that freezes the time dimension out.
CAM makes no allowance for the difference in duration of phonemes in the low and high frequencies. Lower-frequency vowels are invariably much longer than higher-frequency stop plosives, pops, and clicks. There is evidence that some auditory neurons respond only to noise bursts, and some only to frequency-changing signals (see Greenberg and Ainsworth reference) {{1}}[[1]] Greenberg, S., Ainsworth, W., eds., Listening to Speech: An Auditory Perspective, 2006. Mahwah, NJ: Lawrence Erlbaum Associates [[1]]. Clearly a whole host of vital intelligibility cues to the natural hearing system are unaccounted for in standard audiometry.
One way to obtain the “frequency map” so fundamental in audiometry is to use damped wave trains that are shortened as frequency is increased. Damped Wave Trains (DWT) are characterized as frequency-controlled signals with amplitudes that diminish progressively with time, as shown in the example below.
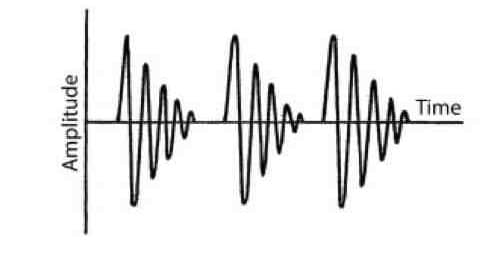
Figure 1. Illustration of a Damped Wave Train.
The key word in that definition is time! Victoreen’s rigorous work with DWTs showed substantial increases in measurement accuracy over pure tones. Recall, too, that temporal integration studies indicate that short-duration signals require more energy for detection in a classic time/intensity tradeoff. Full loudness integration is not reached until around 100 milliseconds. Hence, to represent speech-related “level by frequency” audibility “thresholds” more appropriately, it makes sense to use shorter-duration DWTs in the high frequencies and longer ones in the lower frequencies. Victoreen, along with Ken Berger and others, made arguments for DWTs, but the inertial drag of the traditional audiogram ship has proved very difficult to alter.
A third critique in this micro-exposé of the calculus of hearing pattern mapping is that the pre-fixed frequencies of the audiogram may miss significant auditory micro-structure. Several studies have observed differences of as much as 15 dB in test regions of just 1/10 of an octave. If a two-dimensional (level by frequency) map is the desired goal of the test, the standard convention of choosing frequencies in tidy fractional ratios of 1000 Hz will presumably miss relevant detail. On that basis, a continuous-frequency, automatic, self-recorded Bekesy-type protocol could arguably be an improvement, especially if damped wave trains of decreasing durations were used.
Finally, there is this simple question: “Why map barely audible levels when the goal is to achieve Most Comfortably Clear listening experiences for everyday speech?” A simple MCL for speech is enormously informative regarding gain level requirements, as it is not difficult to convert to a mid-level gain. (Simply put, speech is calibrated with a 20-dB (okay, 19!) pad on the audiometer. Hence, the SPL level for a 70-dB-MCL represents approximately 90 dB SPL. Since speech is estimated to arrive at a listener’s head at 68 dB SPL, it could be argued that a rough gain value for the speech frequencies would be 22 dB.
As noted in the Schweitzer reference, further adjustments to improve clarity may be necessary, but the speech gain principle is a reasonably instructive guide.
There is evidence that listeners can reliably “dial in” to preferred listening levels when given the enabling tools. A number of new fitting approaches incorporate that assumption. In fact, it was maps of supra-threshold equal loudness and/or MCL levels for DWTs that were the basis for fitting approaches that have fallen to the wayside over time. So, isn’t it time to revisit alternative first-level psychometrics for the purpose of delivering amplification when auditory deficits need to be addressed for communicative stress?
We hope this post will be recognized for its intended purpose: to arouse discussion. Long live the audiogram … but maybe not for hearing aids.
A host of supportive references are available, but in the interest of space we encourage readers to consider the following: {{2}}[[2]] Moeller, A, Sensory Systems, 2nd ed., 2012. Richardson, TX: Aage Moeller Publishing [[2]]

Robin Donnelly

H. Christopher Schweitzer
H. Christopher Schweitzer, PhD, is Senior Auditory Scientist at Able Planet. He has a long history of research and clinical activity and continues to own the Family Hearing Centers of Colorado. Robin Donnelly, BA, AA, is assistant manager of the Hearing Health Division of Able Planet, where she works in customer service and supports product development at the Colorado headquarters.




I think there is a lot of food for thought in this blog. Stay with it Chris. Earl
Thank you, thank you Chris and Robin. All the information we DON’T include and should if we are to fit hearing aids better.
I used John Victoreen’s Equaton to fit hearing aids for many, many years. I would still be using the approach if the equipment was stil producing damped wave trains (DWT)with consistency. I am interested in a computer generated DWT loudness comparator. Does anyone know of one or I am wondering if it can be produced for me….Once you use supra threshold measures you will never go back to audiogram based fittings. If anyone has any suggestions please contact me!
Please call me re this concept. I have used Victoreen’s fitting method in the past and am interested in updating and continuing the fitting procedure.
Robert D. Gwyn,AuD. 570 253-7323
I can understand the basis for the arguments against using pure tones but it is what most clinics are equipped with and what most medico-legal cases and govt bodies accept. Perhaps it is time to completely separate audiograms from hearing aid prescriptions to allow for the use of supra-threshold measures in aid fitting providing verification procedures also follow suit