
WASHINGTON, DC — Hearing loss is a rapidly growing area of scientific research as the number of baby boomers dealing with hearing loss continues to increase as they age.
To understand how hearing loss impacts people, researchers study people’s ability to recognize speech. It is more difficult for people to recognize human speech if there is reverberation, some hearing loss, or significant background noise, such as traffic noise or multiple speakers.
As a result, hearing aid algorithms are often used to improve human speech recognition. To evaluate such algorithms, researchers perform experiments that aim to determine the signal-to-noise ratio at which a specific number of words (commonly 50%) are recognized. These tests, however, are time- and cost-intensive.
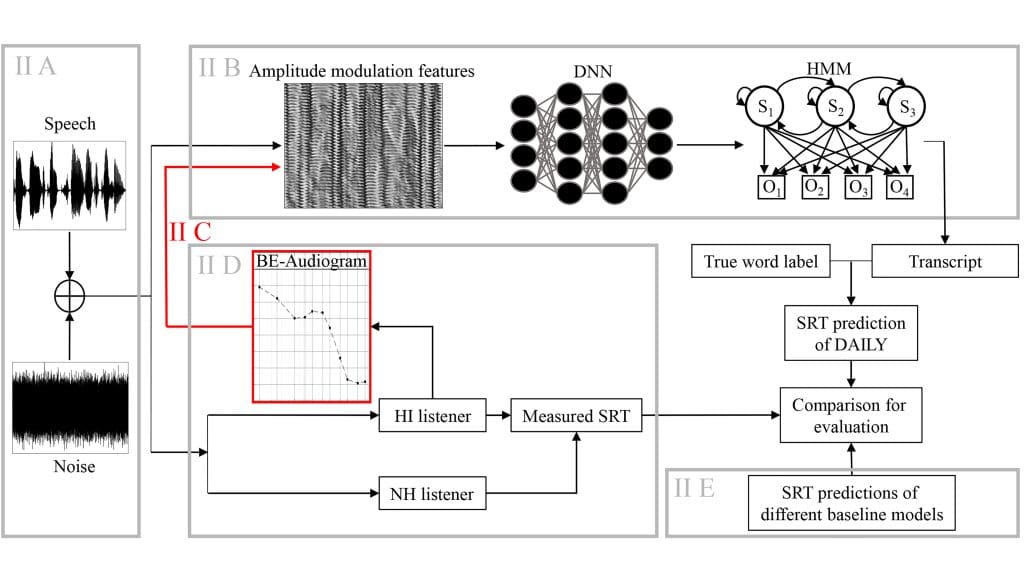
Overview of the human speech recognition model. Image credit: Jana Roßbach
In The Journal of the Acoustical Society of America, published by the Acoustical Society of America through AIP Publishing, researchers from Germany explore a human speech recognition model based on machine learning and deep neural networks.
“The novelty of our model is that it provides good predictions for hearing-impaired listeners for noise types with very different complexity and shows both low errors and high correlations with the measured data,” said author Jana Roßbach, from Carl Von Ossietzky University.
The researchers calculated how many words per sentence a listener understands using automatic speech recognition (ASR). Most people are familiar with ASR through speech recognition tools like Alexa and Siri.
The study consisted of eight normal-hearing and 20 hearing-impaired listeners who were exposed to a variety of complex noises that mask the speech. The hearing-impaired listeners were categorized into three groups with different levels of age-related hearing loss.
The model allowed the researchers to predict the human speech recognition performance of hearing-impaired listeners with different degrees of hearing loss for a variety of noise maskers with increasing complexity in temporal modulation and similarity to real speech. The possible hearing loss of a person could be considered individually.
“We were most surprised that the predictions worked well for all noise types. We expected the model to have problems when using a single competing talker. However, that was not the case”
–Jana Roßbach
The model created predictions for single-ear hearing. Going forward, the researchers will develop a binaural model since understanding speech is impacted by two-ear hearing.
In addition to predicting speech intelligibility, the model could also potentially be used to predict listening effort or speech quality as these topics are very related.
Link to article: A model of speech recognition for hearing-impaired listeners based on deep learning
DOI: 10.1121/10.0009411
Source: ASA



