

NEW YORK, NY — Scientists from Columbia University, led by Dr. Nima Mesgarani, have made significant strides in understanding how the human brain processes speech in noisy environments. Their research, published in the open-access journal PLoS Biology, combines neural recordings and computer modeling to reveal the brain’s remarkable mechanisms when it comes to deciphering speech amidst background noise.
One of the challenges faced by individuals trying to comprehend speech in crowded settings is the overshadowing effect of other voices. Increasing the volume of all sounds indiscriminately proves ineffective, while current hearing aids, designed to amplify intended speech, lack the necessary precision for practical use.

Difficulty hearing speech in the presence of background noise continues to be one of the biggest complaints from hearing aid users
Exploring How Brain Handles Speech in Noisy Environments
To study how the brain handles speech in noisy environments, the researchers implanted electrodes in the brains of epilepsy patients undergoing surgery. These electrodes allowed the team to record neural activity while the patients focused on a single voice, even when it was obscured by another voice or subdued by it. Analyzing the gathered neural data, the researchers developed computational models that offered insights into how the brain encodes speech information.
The results of the study revealed intriguing findings. The brain encodes phonetic details of speech differently based on the ease of hearing and the listener’s attention. Both the primary and secondary auditory cortex play vital roles in encoding “glimpsed” speech, where the desired speech is partially obscured by louder voices. Importantly, the encoding of attended speech is more pronounced in the secondary cortex.
In contrast, the encoding of “masked” speech, where the desired speech is quieter than the surrounding noise, only occurs when it is the attended voice. Notably, the encoding of “masked” speech takes place later in the processing stages compared to “glimpsed” speech. These findings provide crucial insights into the brain’s mechanisms for speech perception in noisy environments.
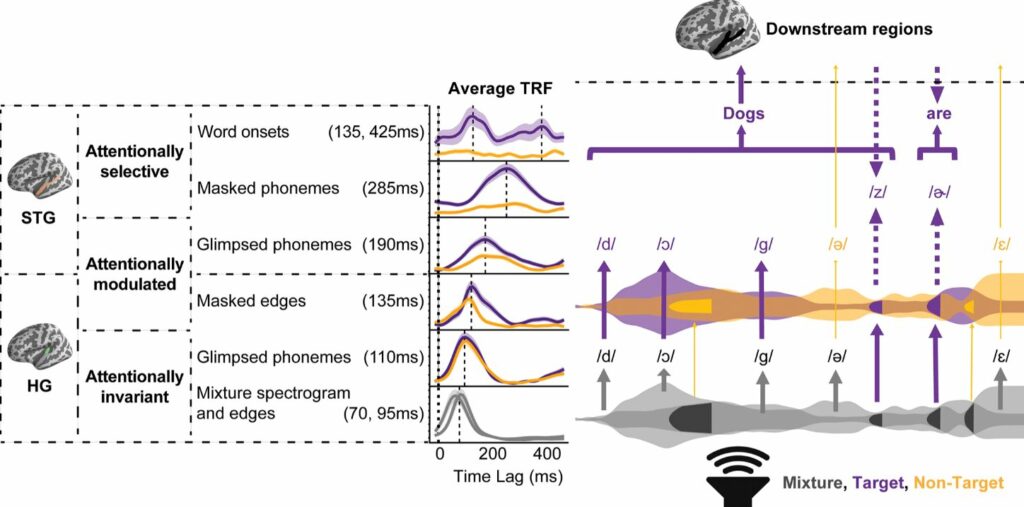
Model of speech encoding in multitalker speech. (Gray: mixture, purple: target, yellow: non-target). In the bottom row, the mixture signal, represented as 2 overlapping envelopes in gray, is first processed in HG acoustically through encoding of the spectrogram and acoustic edges. Masked acoustic edges are represented in dark gray. In the next row, phonetic information that is glimpsed in the mixture is encoded in HG invariant to attention. Both mixture acoustics and glimpsed phonetic features are encoded invariant to attention. Masked edges are then recovered in HG for both talkers with an effect of attention, showing evidence for stream segregation. The masked edges in the first row are shown to be restored with attentional modulation in the third row. In the fourth row, the encoding of glimpsed phonetic features in STG becomes modulated by attention, as indicated by the different thicknesses of arrows extending from the glimpsed phonetic features in the second row. Next, masked phonetic features are recovered in STG only for the target talker with a time relative to glimpsed phonetic features. It is unclear whether bottom-up repair (upward arrow) or top-down restoration (downward arrow) is involved in encoding masked speech. Finally, in the top row, glimpsed and masked phonetic information is integrated to form words. Beyond this point, meaning can be derived from the words of the target talker, while glimpsed non-target phonetic features may also influence the listener. HG, Heschl’s gyrus; STG, superior temporal gyrus. Image credit, PLoS Biology
Implications for Future Hearing Aid Technology
The implications of this research are far-reaching, particularly in the development of hearing aid technology. By decoding the “masked” segment of intended speech separately, auditory attention-decoding systems could be enhanced, leading to improved brain-controlled hearing aids that effectively isolate attended speech.
Dr. Vinay Raghavan, the lead author of the study, emphasized the brain’s ability to recover missed speech information when background noise is too loud. Additionally, the brain can capture fragments of speech that the listener is not directly focused on, but only when the intended speaker’s voice is relatively quiet in comparison.
This latest research offers new avenues for potentially refining today’s hearing aid technology and improving speech comprehension in challenging acoustic environments.
Reference:
- Raghavan VS, O’Sullivan J, Bickel S, Mehta AD, Mesgarani N. Distinct neural encoding of glimpsed and masked speech in multitalker situations, PLoS Biology (2023). DOI: 10.1371/journal.pbio.3002128



